 threat intelligence
threat intelligence
Not every cybersecurity practitioner thinks it’s worth the effort to figure out exactly who’s pulling the strings behind the malware hitting their company. The typical incident investigation algorithm goes something like this: analyst finds a suspicious file → if the antivirus didn’t catch it, puts it into a sandbox to test → confirms some malicious activity → adds the hash to the blocklist → goes for coffee break. These are the go-to steps for many cybersecurity professionals — especially when they’re swamped with alerts, or don’t quite have the forensic skills to unravel a complex attack thread by thread. However, when dealing with a targeted attack, this approach is a one-way ticket to disaster — and here’s why.
If an attacker is playing for keeps, they rarely stick to a single attack vector. There’s a good chance the malicious file has already played its part in a multi-stage attack and is now all but useless to the attacker. Meanwhile, the adversary has already dug deep into corporate infrastructure and is busy operating with an entirely different set of tools. To clear the threat for good, the security team has to uncover and neutralize the entire attack chain.
But how can this be done quickly and effectively before the attackers manage to do some real damage? One way is to dive deep into the context. By analyzing a single file, an expert can identify exactly who’s attacking his company, quickly find out which other tools and tactics that specific group employs, and then sweep infrastructure for any related threats. There are plenty of threat intelligence tools out there for this, but I’ll show you how it works using our Kaspersky Threat Intelligence Portal.
A practical example of why attribution matters
Let’s say we upload a piece of malware we’ve discovered to a threat intelligence portal, and learn that it’s usually being used by, say, the MysterySnail group. What does that actually tell us? Let’s look at the available intel:
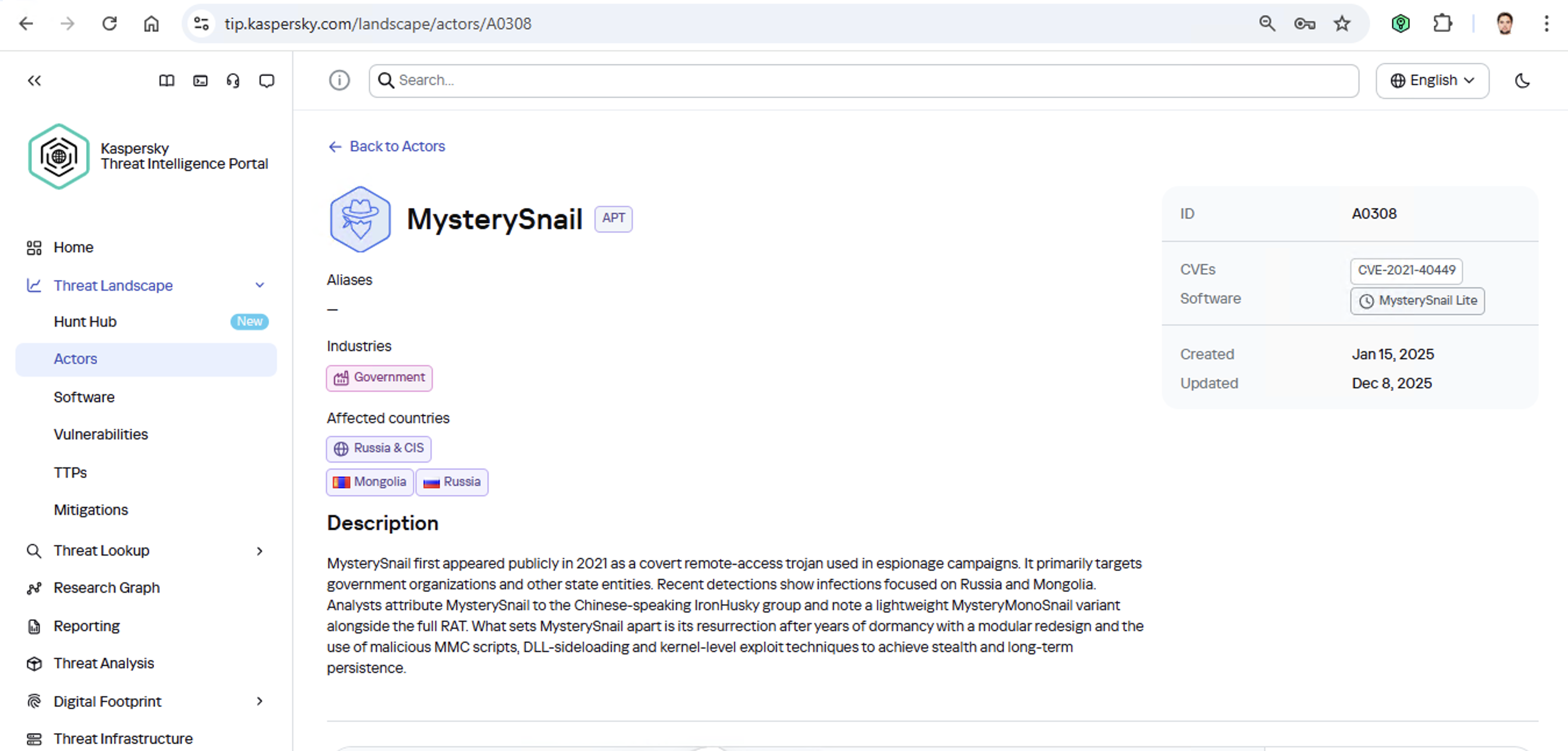
First off, these attackers target government institutions in both Russia and Mongolia. They’re a Chinese-speaking group that typically focuses on espionage. According to their profile, they establish a foothold in infrastructure and lay low until they find something worth stealing. We also know that they typically exploit the vulnerability CVE-2021-40449. What kind of vulnerability is that?
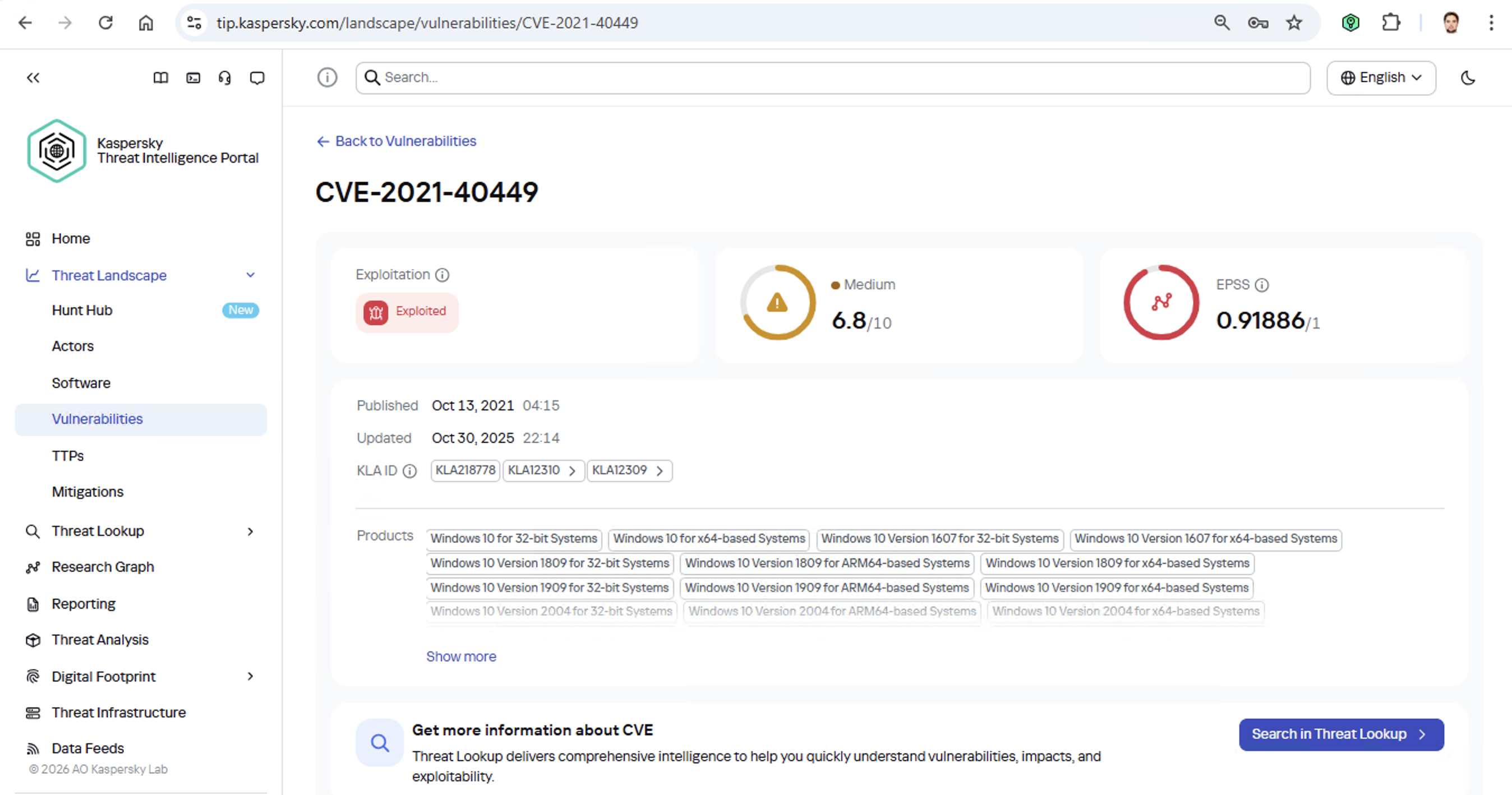
As we can see, it’s a privilege escalation vulnerability — meaning it’s used after hackers have already infiltrated the infrastructure. This vulnerability has a high severity rating and is heavily exploited in the wild. So what software is actually vulnerable?
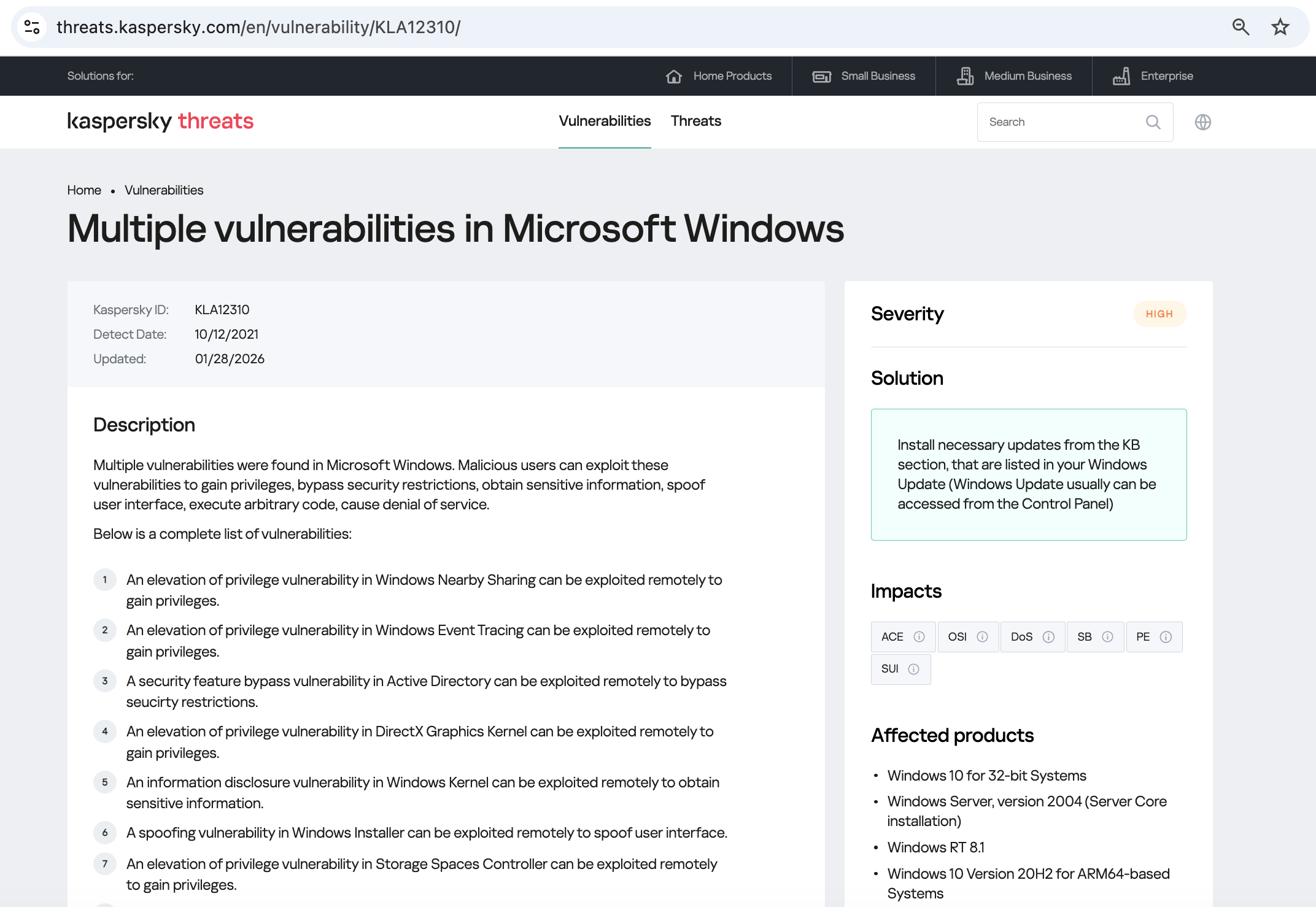
Got it: Microsoft Windows. Time to double-check if the patch that fixes this hole has actually been installed. Alright, besides the vulnerability, what else do we know about the hackers? It turns out they have a peculiar way of checking network configurations — they connect to the public site 2ip.ru:

So it makes sense to add a correlation rule to SIEM to flag that kind of behavior.
Now’s the time to read up on this group in more detail and gather additional indicators of compromise (IoCs) for SIEM monitoring, as well as ready-to-use YARA rules (structured text descriptions used to identify malware). This will help us track down all the tentacles of this kraken that might have already crept into corporate infrastructure, and ensure we can intercept them quickly if they try to break in again.
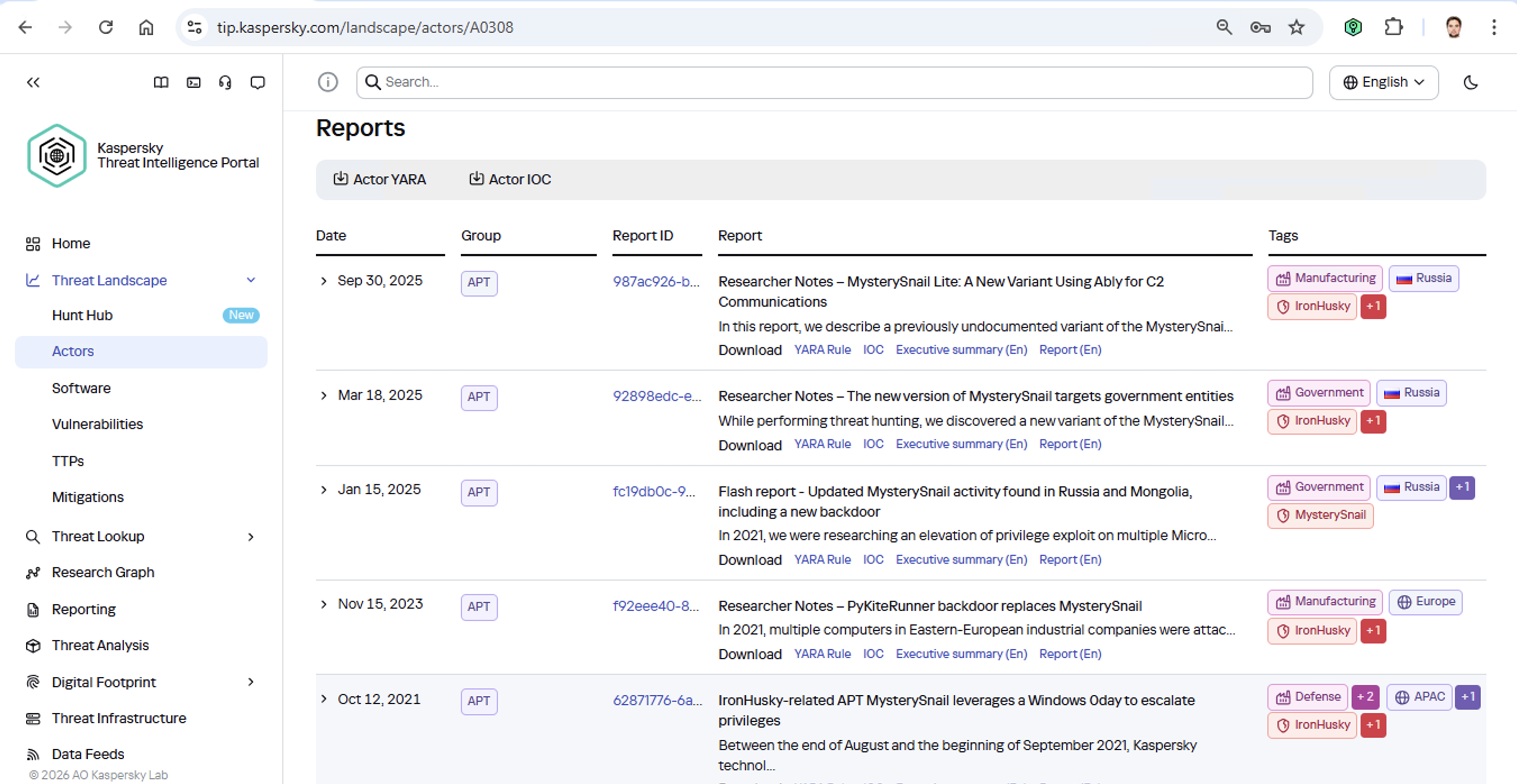
Kaspersky Threat Intelligence Portal provides a ton of additional reports on MysterySnail attacks, each complete with a list of IoCs and YARA rules. These YARA rules can be used to scan all endpoints, and those IoCs can be added into SIEM for constant monitoring. While we’re at it, let’s check the reports to see how these attackers handle data exfiltration, and what kind of data they’re usually hunting for. Now we can actually take steps to head off the attack.
And just like that, MysterySnail, the infrastructure is now tuned to find you and respond immediately. No more spying for you!
Malware attribution methods
Before diving into specific methods, we need to make one thing clear: for attribution to actually work, the threat intelligence provided needs a massive knowledge base of the tactics, techniques, and procedures (TTPs) used by threat actors. The scope and quality of these databases can vary wildly among vendors. In our case, before even building our tool, we spent years tracking known groups across various campaigns and logging their TTPs, and we continue to actively update that database today.
With a TTP database in place, the following attribution methods can be implemented:
- Dynamic attribution: identifying TTPs through the dynamic analysis of specific files, then cross-referencing that set of TTPs against those of known hacking groups
- Technical attribution: finding code overlaps between specific files and code fragments known to be used by specific hacking groups in their malware
Dynamic attribution
Identifying TTPs during dynamic analysis is relatively straightforward to implement; in fact, this functionality has been a staple of every modern sandbox for a long time. Naturally, all of our sandboxes also identify TTPs during the dynamic analysis of a malware sample:
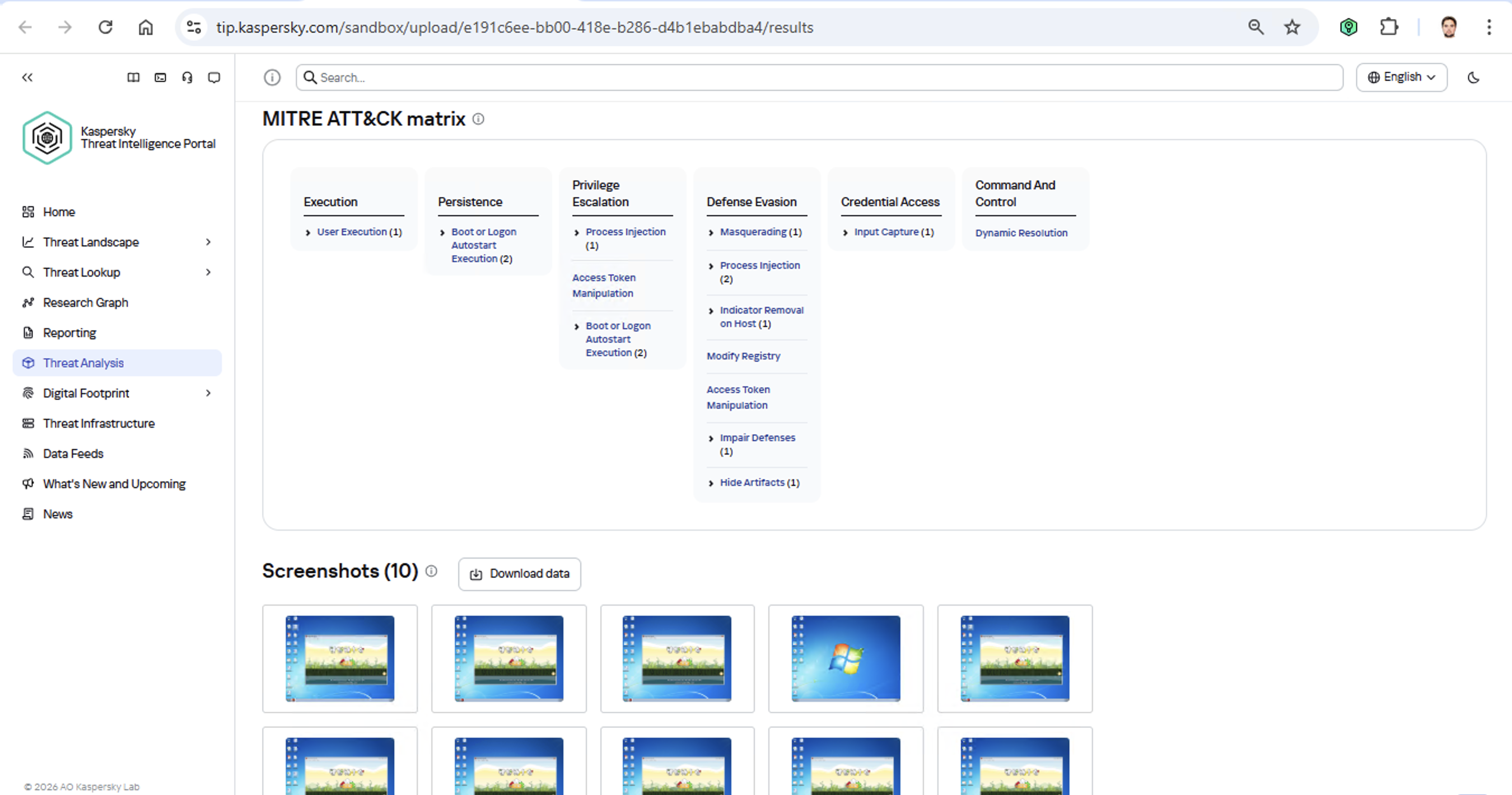
The core of this method lies in categorizing malware activity using the MITRE ATT&CK framework. A sandbox report typically contains a list of detected TTPs. While this is highly useful data, it’s not enough for full-blown attribution to a specific group. Trying to identify the perpetrators of an attack using just this method is a lot like the ancient Indian parable of the blind men and the elephant: blindfolded folks touch different parts of an elephant and try to deduce what’s in front of them from just that. The one touching the trunk thinks it’s a python; the one touching the side is sure it’s a wall, and so on.

Technical attribution
The second attribution method is handled via static code analysis (though keep in mind that this type of attribution is always problematic). The core idea here is to cluster even slightly overlapping malware files based on specific unique characteristics. Before analysis can begin, the malware sample must be disassembled. The problem is that alongside the informative and useful bits, the recovered code contains a lot of noise. If the attribution algorithm takes this non-informative junk into account, any malware sample will end up looking similar to a great number of legitimate files, making quality attribution impossible. On the flip side, trying to only attribute malware based on the useful fragments but using a mathematically primitive method will only cause the false positive rate to go through the roof. Furthermore, any attribution result must be cross-checked for similarities with legitimate files — and the quality of that check usually depends heavily on the vendor’s technical capabilities.
Kaspersky’s approach to attribution
Our products leverage a unique database of malware associated with specific hacking groups, built over more than 25 years. On top of that, we use a patented attribution algorithm based on static analysis of disassembled code. This allows us to determine — with high precision, and even a specific probability percentage — how similar an analyzed file is to known samples from a particular group. This way, we can form a well-grounded verdict attributing the malware to a specific threat actor. The results are then cross-referenced against a database of billions of legitimate files to filter out false positives; if a match is found with any of them, the attribution verdict is adjusted accordingly. This approach is the backbone of the Kaspersky Threat Attribution Engine, which powers the threat attribution service on the Kaspersky Threat Intelligence Portal.

 Tips
Tips